Does your model have a lot of old clutter in it? Units that don’t run; products you don’t make anymore? I know clearing out old stuff is a little stressful – What if I break something? What if I need to run some historical cases? But cleaning up your model can make it easier to understand, reduce run time and improve stability (inactive options are chaos-food!), so it is worth putting some time in, now and again, to have a tidy up. Unused pool qualities are a good decluttering target, as they are easily identified and can usually be removed just by taking out the initial estimates.
GRTMPS sets up recursion structure for every pool property for which you give an initial estimate, whether it is needed for the model or not. The impact of unused qualities is minimized. There won’t be any warning messages about missing contributions, for example or any step bound or penalty structure in the matrix. You won’t see them in the recursion tracking. But we don’t remove them. We have to assume that they are there to provide useful information. Afterall, why would be put them in if you didn’t want to see them in the reports? So, if there is surplus stuff that you genuinely don’t need, you have to do some housework to be rid of it. You know the drill: "How long has this been here? When did you last use it?"
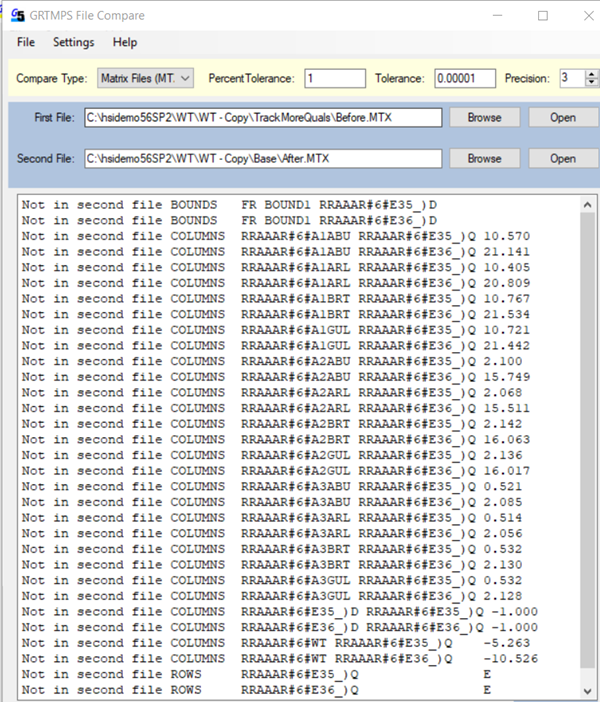
To see how a particular pool quality is used, you can look in the matrix (MTX) file. (The Recursion Monitor shows you which qualities are tracked and where the pool is used, but not which qualities in which uses.) Find the part of the COLUMNS section where the vectors end with _)D. This extract has some quality location-period-pool-property-“D” error columns for pool AR# at location RR in period AA.

Each intersects with its own “Q”-row with a -1.0. The Q rows are fixed to zero to drive the error vector to be equal to the difference between the assumed and actual quality. The error information is used by the rows with the positive entries, which are the assumed distribution factors. For example, the SUL value is needed for the specifications on LSF and RFO, and is also recursed for the VG# pool. (An initial default distribution of 0.25 indicates 4 destinations. There is one missing because it doesn’t use the sulphur quality.) SPM is passed to VG#. The E35 and E36 error vectors, however, connect only to their own Q rows; there are no distributions. So the activity on the error vector has no impact on the optimization. They are unused.
Another way of identifying unused properties is to keep the "After the generation step" RC2 file (OPTION TABPUNX) on the Output General Panel. A generate-only run will be sufficient - no need to do any optimization.

You'll find the RC2 file in the "Other Output Files" node on the Output section of the interface tree. In it you will find TABLE 181.P, a list of all the qualities to be recursed. The ones that don’t have any destinations are marked UNUSED.
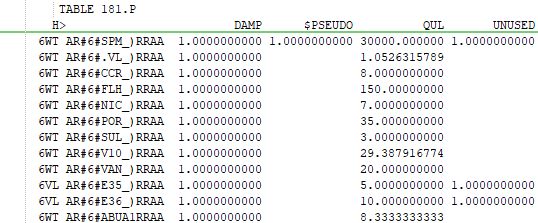
Some properties may be marked UNUSED even though the error vector has connections, as the quality might not be used at that destination either. So the SPM turns out not to be needed after all.
These UNUSED items, then are your candidates for removal. Before you actually take them out though, do pause a moment to consider if they would be used under some other configuration. Note that this list is both location and period specific. If you have a multi-period model make sure that it is unused in all periods before deciding that it is redundant. Also ask yourself if it might be needed for a different season or set of products, a process unit started up or shut down, for transport to another location in a larger model, etc. If you are sure that they are always unused, and you don’t think they provide sufficiently useful information to be worth carrying just for reporting, they can go.
Make a back-up before you start deleting things, of course, and run Datacheck as you go, to lower the risk of deleting too much. You can remove properties by taking out the initial estimate (Blend quality panel). I suggest doing this in an alternate case, as below, so you can easily revert if something goes wrong. If you are working with table based input you could make your changes in a DATA,MODIFY patch or perhaps it will be enough just to make a copy of the workbooks.
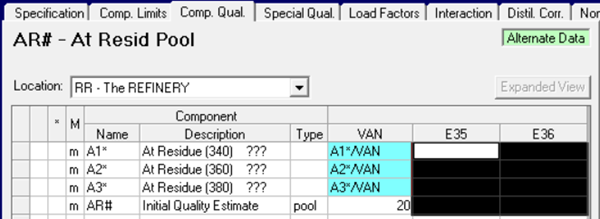
Pseudo properties can be annoyingly difficult to get rid of, by the way, as they don't have initial estimates and the system will create them automatically if the inputs exist. However, if any of the input properties is missing and can be removed, then the pseudo will be dropped. This is unlikely to be possible with properties derived from density or sulphur though. When you are satisfied, you can export the data to an SSI and import it back into the base case. As a confirmation that this has been done correctly, you will see that the “m” markers in the alternate case will have disappeared afterwards. Once the pool no longer needs the property, you may find that you can remove entries for its non-pool components – but be careful in case they are used elsewhere. There may be quality transfer rows (2xx.3) or Yield Quality entries (2xx.5) and related PUPs that could be taken out as well.
You will lose at least a quality tracking row and an error column per period, for each property that you take out, as you can see using the run compare.
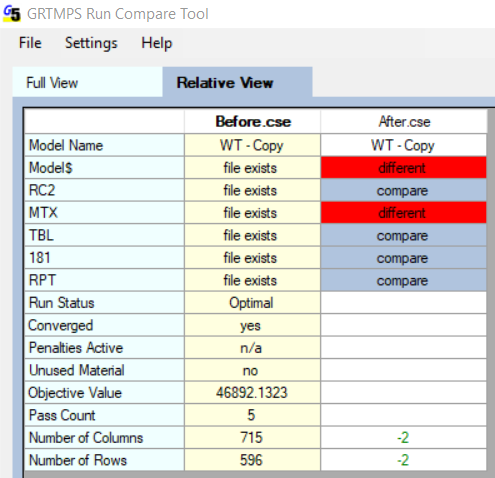
The matrix will have more differences though, as it is likey that it will also lose factors on other rows and columns, making it sparser.
A smaller matrix is always a good goal – less structure means more speed; less inert structure means less variability in your solutions and so should translate into more stability. Don’t however, be surprised if some cases behave worse afterwards – that is the nature of chaotic systems. If possible, assess the impact over a range of cases; you should find that on balance the model behaves better.
If you are still in the mood for cleaning up afterwards, you could use the PSI Analyzer to check for unnecessary AR dependencies, and sort out any warning messages in the Datacheck report. You could even tidy your desk - or maybe that's going too far.
28th May 2021
You may also use this form to ask to be added to the distribution list so that you are notified via e-mail when new articles are posted.