This is an introduction to the fundamental issue that brought recursion into refinery planning models and how this approximation allows us to optimize the qualities of products where some of the components are themselves mixtures of varying qualities. The pooling problem (C. A. Haverly, Studies of the Behaviour of Recursion for the Pooling Problem, ACM SIGMAP Bulletin. 1978.) exists in refinery LP models whenever there is a group of materials that have been modelled as separate streams – because they come from different feeds or different unit operating conditions – for example atmospheric residue cuts from a number of crudes that are going to be processed at the same time.
| If they were not pooled, and could go separately to each use, the model would be able to over-optimise, So, for example, all the lower sulphur atres streams could be used in the low sulphur fuel oil as if they were being kept in a separate tank. That would be all right if the crude oils were being run at different times, but not possible if the crudes are running together. | 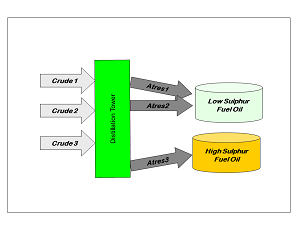 |
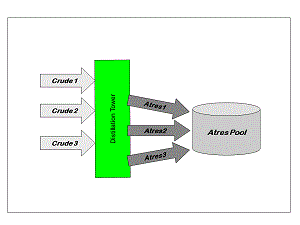 |
It is not possible to write a linear constraint which forces the atres’s to go to each product in the same proportions. So we pool them instead. |
| Why does this pooling create a problem? Because when blended products, such as gasoline, diesel and fuel oils are modelled, the property value of each component is needed in order to constrain the average product quality to meet the specification | 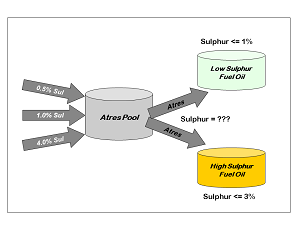 |
Most specifications limit the simple weight or volume average of the qualities of the components in a blend. “Quantity” is the variable in the model for the amount of each component in the blend and “Property” is a co-efficient representing its quality value, summing over all components.
Σ(Property * Quantity)
---------------------------- <= Specification
Σ ( Quantity)
Re-arrange to be linear for the LP as Σ (Property * Quantity) – Specification * Σ (Quantity) <= 0
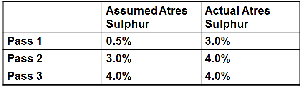 |
This recursion continues until the assumed and actual qualities match within the tolerance chosen. Such a solution is said to be converged and can be accepted as a useable result because it is internally consistent. The quality that the pool takes into the products is the average of its component values. |
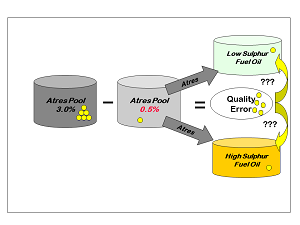
Although simply recursing the quality values in this way can lead to a converged solution, it is not necessarily a good answer to the question. With no connection between the actual pool quality and the product specification, there is no incentive to drive the pool to the best quality. The model could be started with a low estimated sulphur value for the atres pool but process only sour crudes. No matter how high the sulphur content of the atres cuts, the model would still be able to blend them as if they were low sulphur on the first pass. On the second pass, with the updated quality, it would only be possible to make the HSFO product and no way for the model to see that lowering the atres sulphur would make the more valuable LSFO product possible.
Recursion is more effective if some connection is made between the actual pool properties and the qualities of the final products that it blends into. This can be done by keeping track of the quality error - the difference between the assumed and actual quality – and sharing this between the products as an adjustment to the specification quality balance. Quality error can be counted by treating the assumed quality as a requirement on the pool but adding an error vector to make a balance between actual and assumed properties.
Σ (Quality * Quantity) – Assumed * Σ (Quantity) + ERROR = 0
If the assumed sulphur of the pool is 0.5% but it is made from one tonne of 3.0% sulphur atres (3.0 * 1 – 0.5 * 1 – ERROR = 0) then the error vector will be equal to 2.5 If the actual value were less than the assumed, the error vector would be negative, so these are always defined as FREE vectors in the matrix. Note that the error vector is always equal to the difference in quality times the quantity of pool made, rather than simply the difference in average quality. (Quality in the model, just as in the refinery, does not exist by itself, but is a property of a material flow and the quality changes apply to all of the material.) So if there were two tonnes of atres the error vector would be equal to 5.0 (3.0 * 2 – 0.5 * 2 – ERROR = 0) Actual pool quality can be calculated as assumed value + error / total, that is 0.5 + 5/2 = 3.0
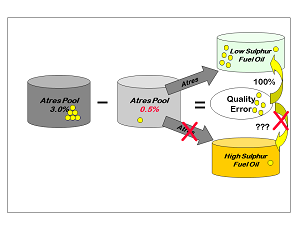
| How should the error adjustment be used? The quality adjustment has to follow the quantity. It needs to be distributed in proportion to the amount of pool that goes to each product, so that the product ends up with the right amount of sulphur. If all the pool goes to LSFO, then so should all the extra sulphur, so that the per cent sulphur in LSFO equals the percent sulphur in the atres pool. |
 |
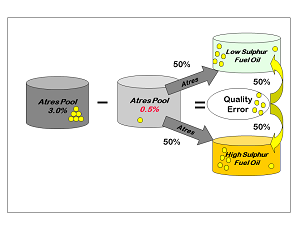 |
If the solution were reversed and all the pool went to HSFO, then so should all the extra sulphur, so that the sulphur in HSFO equals the sulphur in the atres pool. If the pool is divided evenly between the products, then, if the error is also divided evenly, each product will “see” the actual atres sulphur value, instead of the assumed one. |
Adding the right proportion of error to the calculation of product quality, allows the model to perceive the effect of actual pool quality during the optimisation. The LSFO only solution would correctly be found to be infeasible if the atres remains at 3%. (Assuming, for simplicity, that it is the only component in the product.) This gives an incentive to adjust the pool quality, if possible, by changing its composition, in order to arrive at a better solution. So the product specification row is connected to the quality error vector of the pooled components for which an assumed quality is used. The distribution factor is the portion of the pool that blends to that product.
Σ ( Assumed Quality * Quantity) + Distribution Factor * ERROR – Specification * Σ (Quantity) <= 0
 |
With correct distribution factor the product will be blended as if we were using the actual pool quality in the specification row, rather than the assumed value. But, the fraction of the pool that goes into each blend is not something we normally know in advance. It is one of the decisions that we want to optimise. So in order to set up the equations, assumed distribution factors must be used. These are then updated from pass to pass, just like the quality values. Hence the term distributed recursion for this particular form of SLP. |
From Kathy's Desk 20th January 2017.
Comments and suggestions gratefully received via the usual e-mail addresses or here.
You may also use this form to ask to be added to the distribution list to be notified via e-mail when new articles are posted.