 |
Crude evaluation is one of the most common optimization applications in the oil industry. Each of the many grades that are available to process are run through a model in order to predict their contribution to profits. Their value relative to each other gives a “pecking order” of preferred feedstocks for a refinery and the expected margin sets the price you are willing to pay. Even a difference of just a few cents per barrel can correspond to a large sum of money given the quantities involved, so there is a lot of pressure to get this right |
| It is, therefore, very worrying when a crude drops from the top of the list | |
| |
Does it mean that the original evaluation was wrong? What could be causing this instability? Is it real or an artefact of the evaluation process? Here are some things to consider – with suggestions of what you might do to reduce their influence on your decision making.
Local Optimality
Maybe the lower value in the updated evaluation is due to converging on a particularly poor solution. Although we refer to our optimization activities as “LP” in the oil industry, we’ve been solving primarily non-linear problems with “SLP” for decades.
 |
While a converged solution is a feasible answer to the non-linear problem and the best possible answer to the current linear approximation, most non-linear problems have other answers too. Which one you find often depends on where you start. Perhaps you got lucky in the first evaluation and unlucky in the second. When you have time to do more analysis and testing, you may be able to figure out how to adjust the model or your optimization strategy so that the better answer is easier to find, (in a way that doesn’t mess it up for more normal problems where it was already doing okay.) In the meantime, however, if the optimal value seems too low, you should look for another solution. You could try to bias the new case towards a higher value answer by using the 181 file from the better run. |
If that doesn’t boost the value, then the Multi-Start tool is an easy way to explore more of the solution space by using a variety of starting estimates for the pool properties. It generates random variations on pool property estimates from a 181 file.
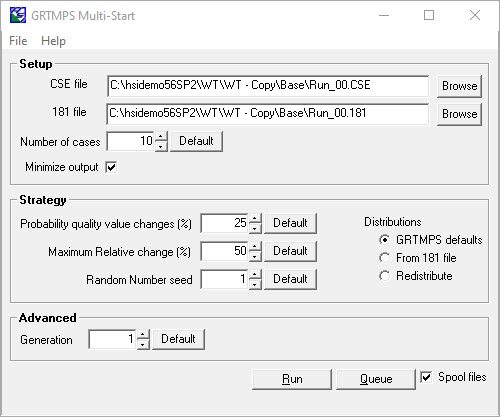
The default is 10 cases and that might be enough to identify a better answer.
Keep Looking
| However, if you don’t find one in your first set of runs, that doesn’t prove that there isn’t one. Maybe the recursion has to take some unusual route to achieve that kind of solution. So "If at first you don’t succeed, try and try again". The more runs you do with the wider range of starting points, the more chance you have of finding that rare combination. Modern multi-core hardware and parallel running make this much more practical than you might think. |  |
If you find a better answer, order has been restored. But if you don’t….
Over Estimate
Could the problem be that the better value was an over-estimate of the worth of the crude due to an underestimate of the value of the base situation? The value of a crude is usually assessed by asking how much the optimal value changes when some quantity of it is substituted for part of a reference crude slate. When you have changed only one thing, it is natural to attribute the change in value to that difference. Maybe, however, the base aspects of the problem solved to a plan that would be better than the original base solution, even without taking the new crude into account. In your second evaluation, that extra uplift effect could be missing from the run for this particular target crude, or present in all of them so it no longer influences the order. Try doing more runs with the base case to see if you have been underestimating its value. Try running it from the input and / or output 181 file of the high value run with the target crude slate as well as multi-starts from its solution.
Noise, Not Signal
There is uncertainty in your model --- in the inputs (prices, assay data), the representations of the operations and the calculations (even with 64-bit). (Nate Silver’s The Signal and the Noise, a highly recommended read on these sorts of issues.) What any model is returning is the underlying "real" value +/- something. Just how big are the differences between the crudes in your list? If the gap between grades is just cents/bbl then maybe it’s within the range of error of the model. You might be attributing too much significance to the precise position in the list. The pecking order might have switched around, the calculated average margin might have gone up or down, but the values should be treated as the same. You need to work out what the noise level in your solutions is. Run multi-starts and try other simple changes that shouldn’t materially affect the outcome to see how much the predicted profit varies, running a variety of case scenarios. Then you can use that information to put error bars around your valuations.
 |
Noise Cancelling: There are some specific sources of noise in SLP problems that you might be able to turn down to make your values more stable. The effects of these technicalities are probably very small most of the time (in other words, don't panic!), but if the range of your valuations is also small, then perhaps they are at least sometimes, big enough to shift relative positions. |
Convergence Tolerances: Some part (hopefully very small because your tolerances are sensible), of the objective value will be made out of exploiting minor inconsistencies that are left although a solution is converged. There is bound to be some variability between runs on the impact of this. SLP models are often started with very tight tolerances, which are relaxed to more practical levels on later passes. You might be comparing runs that were converged to different thresholds. Tighter tolerances overall give less room for this to happen, although that brings a risk of failing to recognize usable solutions.
| So maybe use tighter tolerances when value comparisons are critical, but be more pragmatic about identifying solutions that are sufficiently consistent for practical purposes when working on a plan. Note that I am talking about the tolerances for deciding if the values are close enough to be called the same, not the stopping criteria (RCMINOR); an extensive analysis of the impact of that setting on the runs, found that “D or PQ” was most likely to identify a useable solution without having any particular impact on the objective value. | |
 |
Step Bounding. If you are using Step Bounding to push your model to convergence, it could be that the runs differ in the degree to which bounds are constraining. Runs that take more passes or just happened to oscillate more may have more active step bounds. Look at the high value runs to see where bounds are active… they are marked in the blending reports… and at the low value runs to see if there is a different pattern. You could adjust just the initial bounds for some properties to make them less likely to be limited. Or just delay the starting pass. Just remember, though, that if your model stops converging you won't have any useable solutions at all |
.
The Value Really Changed
We may, however, in the end, have to admit that the change in rank or value is real. That the result is a signal, not noise, and the different valuations are both valid. Even though we can never be certain that there isn’t a better answer, the more runs that we have done without finding it, the less likely it is to be there.
| Perhaps the real problem is the assumption that the crude valuations should be stable. Then the question to ask is not "Why did it change?", but “Why are the values changeable?” |
The changes in the base scenarios between the two evaluations might be more significant than you imagined; even if the refinery configuration is the same, and the general pattern of feeds and product demands is similar, and the optimal value is similar, the economic drivers can be different. Optimization methods for LP problems push everything to the extremes of the constraints (feasibility tolerance 10E-5) and would turn the world upside down to make $0.00001 (optimality tolerance). Small differences, particularly on the margins of limiting constraints, can have a big impact. It might not take much change in the base crude slate, for example, to adjust the sulphur of the diesel pool by 0.002 ppm, but when 9.998 is on-spec and 10.001 is off, then something has to be done to compensate. You might be able to identify this sort of shift by comparing the marginal values on unit capacities and blend specifications between the runs. The goal is to try to make a narrative which explains how the value of your crude reacted to these shifting pressures, based on its yield profile and qualities, so that there is some explanation of why it changed, to justify your revised pecking order.
Robust Optimization
Once you have embraced the idea that crude values are context dependent, the challenge is to take that into account in your planning decisions. A crude whose value is good, but dependent on other assumptions, is probably not be as desirable as one which has a lower value, but keeps it in more circumstances. Looking for strategies that are less sensitive to assumptions is known as “robust optimization”. Instead of doing evaluations against a single set of assumptions, multiple scenarios are evaluated that in some way reflect the uncertainty in the base conditions – such as different price sets for products, or alternative assays when the crude quality is known to vary. Rate the crudes not only on their best value but also taking their worst or typical into account, in some way. More cases to run, again, even if only for the crudes that come in the top of your pecking order, but when you consider the sums involved, well worth the investing in the computer power to do them. So go ask your boss for a 44-core desktop for the planning team; you'll make good use of it.
17th December 2020
365 days without jet lag.
You may also use this form to ask to be added to the distribution list so that you are notified via e-mail when new articles are posted.