A critical requirement for anyone making blended products like gasoline or diesel is that the properties – such as density, sulphur, octane, cloud point - of the final mixtures are within the legally required specifications. Refinery optimization models obviously need to have equations that represent these constraints. Carrying information about quality from feed stocks through to final blends was the original purpose of adding Distributed Recursion to refinery planning models. Much of what happens when that information arrives, however, can still be represented linearly.
Many properties, particularly those related to specific physical characteristics -- such as sulphur, metals content, % of chemical species such as aromatics --- just accumulate in the mix. The average value for the blend will be the total stuff contributed by all the components divided by the total material used. If 50 tonnes of a component that contains 20 ppm sulphur is mixed with 200 tonnes of another component that has 8 ppm, then the mixture will have:
(50t x 20 ppm + 200t x 8 ppm) / (100+200)t = 10.4 ppm
(50t x 20 ppm + 200t x 8 ppm) / (100+200)t = 10.4 ppm
Some properties such as benzene content or octane are blended volumetrically. The method is the same but the quantities will be in m3 or barrels.
When a specification must be met, then the model needs an equation which compares the combined component values to the amount allowed. Generically we can express this as
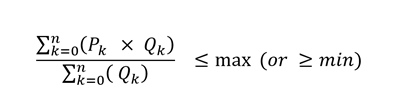
The sum of the Property x Quantity over all the components, divided by the Sum of the Quantity of the components has to be less than or equal to the maximum value specified – and/or greater than the minimum. (I always want to do this as Quality x Quantity, but then they would both be Q). The typical refinery LP model is set up to identify the best recipe for each product, given the available components. The “P”s are co-efficients (that may be updated between recursion passes), and the “Q”s are the variables in the equations, each representing the amount of a component to be used in the blend.
Stated this way, however, the specification can’t be part of a problem that is going to be optimized by the Simplex algorithm. It doesn’t handle variables dividing by each other. Fortunately, a little basic algebra will resolve the issue. Multiply through:
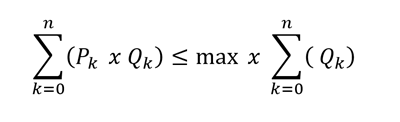
Then subtract to remove the variables from the RHS:
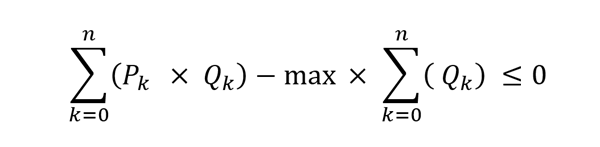
This equation is effectively a quality balance, comparing, as a positive value, all the quality that the components are bringing in to what the specification allows, as a negative value. If the specification is constraining, then the two parts will be equal. If the contribution is less than the max, the equation will have a net negative value indicating give-away. If the contribution were more than the spec, a net positive value, the solution would be infeasible. Although this could be further simplified by making the coefficient on the “Q” vector equal to “P – max”, the delta between the component property and the required average, that would make problems later. Instead, the sum over the Q’s is turned into another variable, “T”, so that it can appear in the equation as a separate element. This requires an additional balance row to drive it to match the total blended:
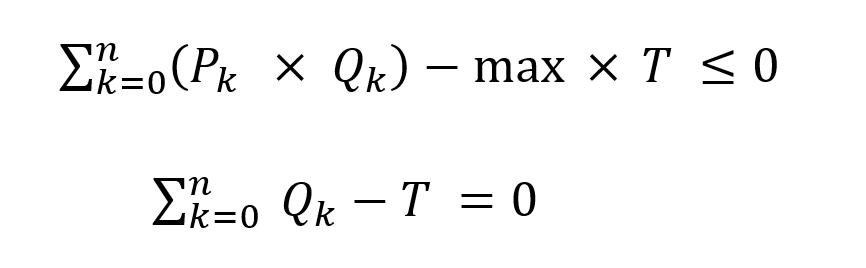
So far, so simple – but there can be complications. What if the Quantity vector units and blend basis of the property don't match?. Refinery LP models are usually set to material balance in weight or volume. The vectors representing the amounts of component going to each blend will be on this model basis. If you are working with a property that averages on the same basis – sulphur in a weight model, or octane in a volume model, the formulation above is sufficient. However, if the basis is opposite, then you need to do some scaling by density to get the right product value.
If Qs are tons and you need to do volume averaging, then, as Volume = Weight/Density, you need to sum over (P x Q/D) for the component contribution. Since Q is a variable, its better to think of it as (P/D x Q) – that is divide each component's property co-efficient by the its density. The density, like the property, could be a constant or a recursed value that will be updated between optimizations. You can’t do this with the specification contribution because you don’t know the density of the blend. No need to estimate and recurse though, as there is a linear formulation. Change the row that drives the value of T, so that it becomes a volume count. Each ton of component contributes a certain volume, M3/KG, to the blend, which is 1/Density – often referred to as specific volume. So the equations become
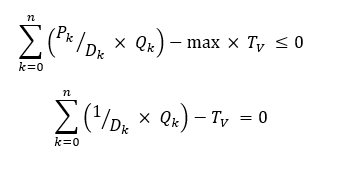
If you are working in a volume model and blending a weight averaging property like sulphur, then you multiply by density:
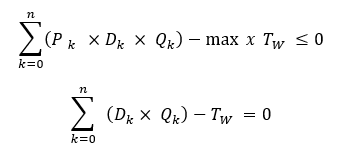
If you are ever tempted to set up a little blend optimizer in Excel (if you are reading this you are probably the sort of person who would be), then formulating the blending equations properly is what gives you an LP problem that solves reliably and quickly, instead of a non-linear problem that needs to be solved iteratively. If you are setting up blend specifications in a GRTMPS model, then all this will happen automatically. You can see the final equations in the matrix or use the Matrix Analyzer to see how a particular solution has balanced out.
You should also take note of the form of the equation when considering the meaning of a marginal value on a specification. What units is it in? How would specification equations balance out if the RHS is relaxed by 1?
This is not the end of the story, as there are often further complications. What if the property of the final blend is not simply a linear average of the component contributions? That brings us into the realms of indices and non-linear blending – topics for another time.
From Kathy's Desk, 5th October 2018
and equations 5 and 6 corrected 10th September 2024 (thank you Benjamin)
P.S. Had fun working out how to use the new(ish) equation editor in Word - Right click to remove brackets being a useful finding. If only they had thought to put in a "none" option in the fractions and script choices.
Comments and suggestions gratefully received via the usual e-mail addresses or here.
You may also use this form to ask to be added to the distribution list so that you are notified via e-mail when new articles are posted.