Haverly’s Matrix Analyzer is a very useful tool for combining matrix structure with the solution values to see how the equations that make up your model are working. If you are trying to analyse marginal values or debug model structures, it is really helpful to have a look at what is going on mathematically. I used to painstakingly cross reference between the matrix (MTX), row and solution files to build parts of the solved model into Excel. Now, I just use the Matrix Analyzer.
The Matrix Analyzer has been included in the Haverly Excel Add-in since the release of GRTMPS v5.1. In order to use it you must set the run to "Include the Matrix Solution" and keep the DBT file on the General panel of the Output node (Earlier versions read from the MDB, but using the DBT is faster).
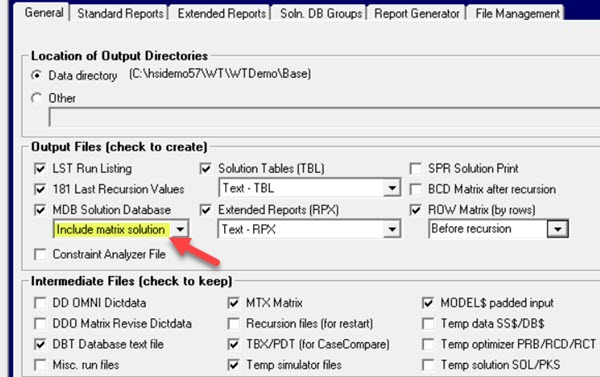
Prior to Version GRTMPS v5.6, you needed to set option SOLTODB in the Advanced panel or Table OPTION.
After you have made the run, you can open the Matrix Analyzer in Excel from the Haverly Menu. Be sure to start in an new, empty workbook.
If you cannot see the menu, you need to install or activate the grtmacro.xlam Add-in that is installed in your GRTMPS system folder. (In most versions of Excel through File: Options: Add-ins: Excel Add-ins.)
Select a model database (not a solution database), then use the drop-down lists to choose a particular case and a run.
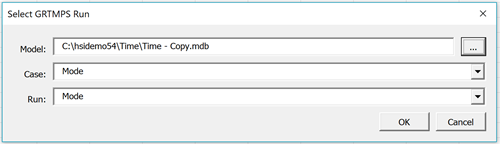
As an example, let's look at the "Time" demo model. We can study the difference between the multi-mode and the block operation versions of the naphtha splitter. Selecting the run creates an empty template in the work book, like so:
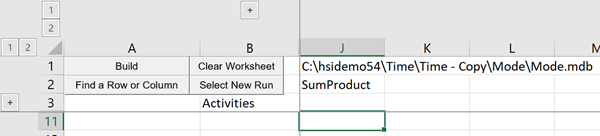
Put your cursor in J2 if you want to start with a column, or A11 to start with a row. Hit the “Find a Row or Column button” to open a list of matrix names. (This is the point at which there will be an error if SOLTODB was not on when the solution MDB was made.)
You can scroll and choose an item to add, or type into the Name Search box to jump. I have chosen the three process limit rows - the ones that end with PL.
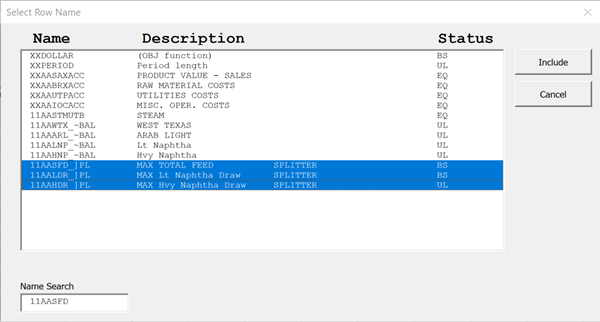
Hit include when you have selected the rows you want. These have two contributing vectors.
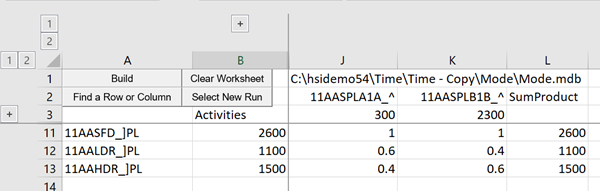
If you want to see descriptions or incentives etc. click on the +’s to expand the grouped rows and columns.

Now we can see that the Heavy Naphtha draw is constraining at its Upper Limit (UL); it has a dual value and zero slack. The other rows are Basic (BS), with non-zero slack values; they are not constraining. (I had to hide a few bits to make the picture small enough, as you might notice by the gaps in the row and column labels.)
How does this compare to the blocked operation case? (Read Tech Note HTN-0005 in the GRTMPS Knowledge Base under Help if you are not familiar with this concept.) Now there are 5 process limits to pick up – the overall feed and the two pairs of light and heavy naptha draw maxima, one set for each block.

There are several interesting things to notice. The RHS of the naphtha draw limits is now zero instead of 1500. The light naphtha draw is limiting on the low sulphur operation, while the high sulphur operation is constrained by the heavy naphtha draw. There are two addition operations, for LS Days and HS Days, that contribute a value to the limit. This value is the negative of the per day maximum that was entered in the process limits panel (Table 111.0). To see how these vectors are controlled, put your cursor on one of the names in row 2 and press the “Build” button.
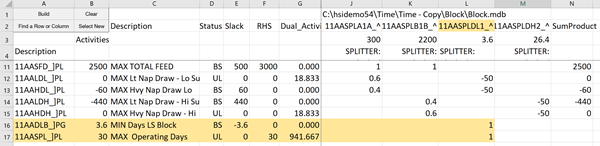
Two new rows are added, highlighted in orange above. These are process limits to control the numbers of days available. To complete the picture of the structure, select each of these rows in turn and click Build. This will add a coefficient on the other day vector and the SumProduct formula, as marked in blue.
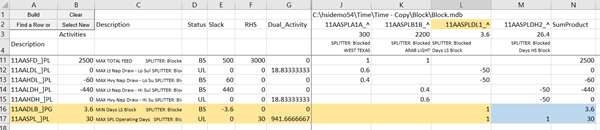
This model is quite small, so you could put the whole thing in the analyzer by continuing to select and build. However most real models are too large to see all at once, so just build up enough of a sub-section so that you can understand how the items you are interested in are working.
The analysis spreadsheets are dynamic. The activities value on the row (Column B) is a constant value from the solution; The SumProduct value to the right of the last matrix vector) shows the result of that formula applied to each row. You can tell you have all the contributions when the SumProduct equals the Activity. You can also use it to check the effect of changing a column activity or coefficient. For example, operation B1B is at 2200 in the block case, but was 2300 in the mode case. By trying the higher value in the block solution, I can see that it would have been infeasible on the HS Heavy Naphtha draw (HDH).
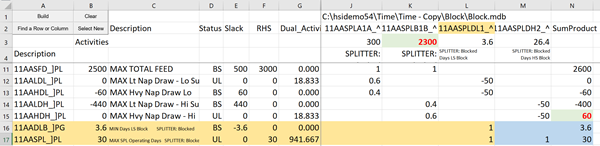
I could make adjustments to the other vector values to try to bring it into balance - increasing the days allocated (11AASPLDH2_^) to generate more capacity on the high sulphur mode. Then reducing the days on the low sulphur block (11AASPLDL1_^) to make it still balance out to the maximum of 30, which would then in turn require a reduction in the amount of feed on the low sulphur, etc, etc - although at some point it would make more sense to turn it back over to Simplex and find the optimal solution - if there is one.
So the Matrix Analyzer lets us see how a solution fits into the equations; how different unit designs translate into different equations, and how changes in solution values effect constraints and other vectors, what a change in the RHS limit would allow the solution to do, and so forth..... All together, it is a very powerful tool. Thanks to Kirby English for kick-starting the addition of this useful feature.
From Kathy's Desk, 31st July 2018.
Comments and suggestions gratefully received via the usual e-mail addresses or here.
You may also use this form to ask to be added to the distribution list so that you are notified via e-mail when new articles are posted.