De-pooling requires composition tracking qualities so we know what streams went into the pool and corresponding driver rows so that this information can be used to control the modes that are run. GRTMPS’s auto-depooling feature can be used to set most of this up automatically. The VDU representation from the HCAMSIM CPO demo model shows how it is done.
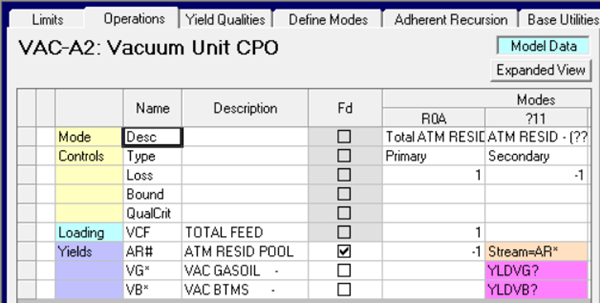
The atres pool, AR#, is a blend of the individual crude atres streams, the AR* set. The primary mode consumes the pool and the generic crude mode, ?11, has the component stream in the feed row (selected via a right-click option on the cell). The system understands this to mean that when the mode is expanded, operation ABC11 is to be controlled by the fraction of ARABC that is in the pool AR#. If you put 8000 bbl through the unit, which has 25% atres from ABC by content, then the ABC mode will be used for 2000 bbl. This example is from a cut-point optimization (CPO) model, so the yields on the processing vector are pink tag codes for the recursed values that come from HCAMS. If the model had pre-cut crudes instead, then there would be blue tags that link to the static values in the crude database.
How can we apply this to a crude tower? The most direct translation would be to pool the crudes and then list each as a component on the secondary vectors. As each of the component streams has a distinct name, you would have to write out a mode for every crude. If you are still going old-school and your crude data input is in tables– the you could do this, writing it into the template for generating the file for each crude. However, the database input system doesn’t offer the crude streams or ??? in the drop-down list for the “Select Depooling component Stream” – so we have to be a little creative.
The trick is to run through crudes through a dummy process unit to rename them.
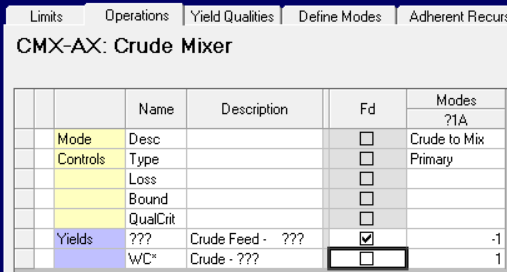
|
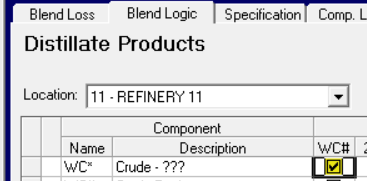
Blend the new stream set into a pool:
|
Note that using the “*” and “?” placeholders in the names means that the structure will automatically expand to any new crudes added to the model, which is an advantage over pooling the crudes directly, even if the system is enhanced to allow that, as new crudes would need to be added to the component quality list and the blend logic. |
Feed the pool to all the units that share this slate, depooling into WC*.
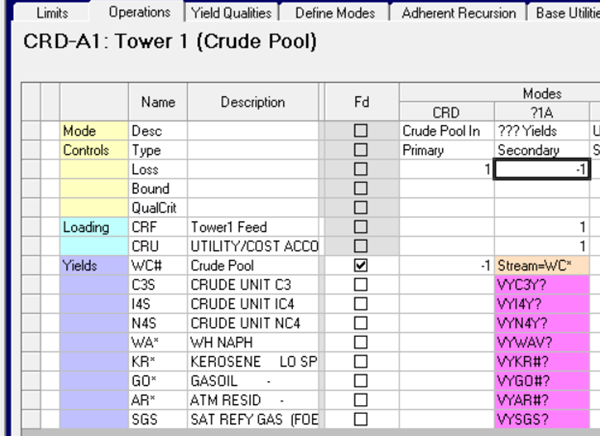
The unit report for the mixer shows the selected slate.
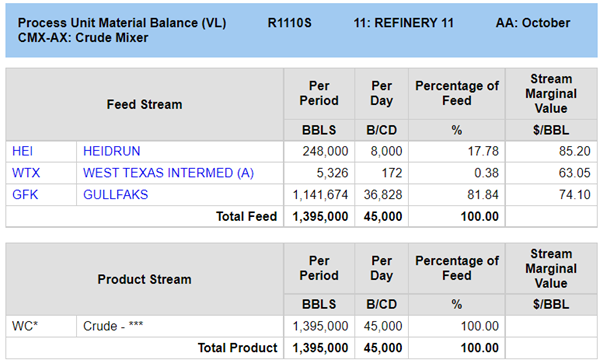
The mass balance reports for the towers will show the combined yields:
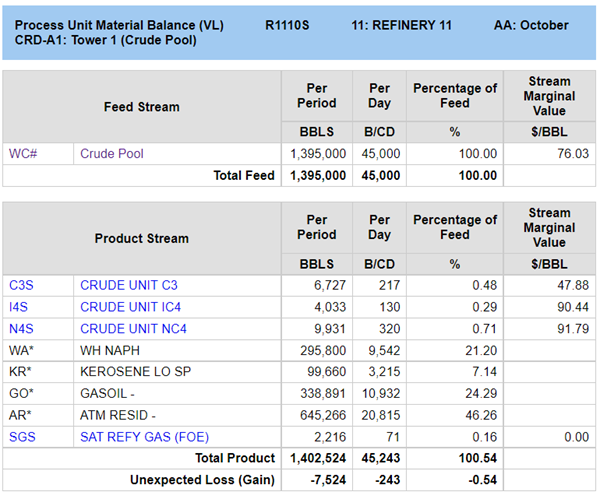
If you want to see the yield breakdown by crude, then choose report option “A” instead of “S” – or even “M” for a balance by operation breakdown (in the classic style HTML only).
Not quite done though. All pools are expected to have a DEN entry at least (or an API from which it can be calculated), so you must put something in for WC# and its WC* components.
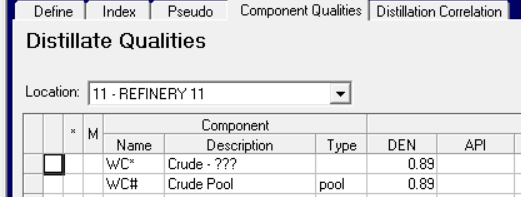
This is enough to ensure that there are no warning messages. However, using a constant value for WC* won’t give you an accurate weight/volume conversion in the blending or unit reports – and will almost certainly make a discrepancy between them and the reported purchases and overall location I/O balances. To do it properly, you need to use the density of each crude. If the model has a crude database, you can link to it here in the Component Qualities panel, as you would for any other stream (having made a connection between WC* and a stream tag from the crude database on the Stream panel), replacing the hard coded number with a blue tag.
For the CPO model, the density needs to be picked up from the assay in the unit tables. Link the unit to HCAMSdirect to access that information.
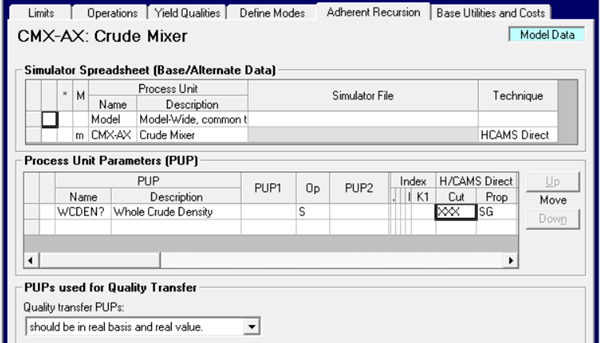
Define a PUP Name (with “?” at the end to generate one for each crude) to pick up the whole crude density. Since we are retrieving a constant, there are no PUPn parameters. XXX is the default code for “Whole Crude Entered” values and Prop will be the tag that you use for density in HCAMS. A couple of details to note. One - If your project is still using 2-character cut names, then use “XX” instead, so that the lengths match. Two - Choose the right density property. Your product blending is likely to be need density at n degrees but the calculations of crude weight/volume should be made with Specific Gravity (according to my engineering colleagues). Make a consistent choice in your PUP definitions and in the Whole Crude properties panel on the Crude Setup node so everything matches.
The PUP is used on the Yield Qualities panel to overwrite the placeholder in the blending data.
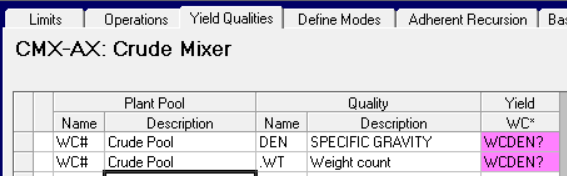
As usual, when adjusting density I am also adjusting the internal conversion factor – which is .WT for this volume model and so equal to density. For a weight balanced model, there needs to be a .VL entry that will use another PUP code calculated as 1/WCDEN?.
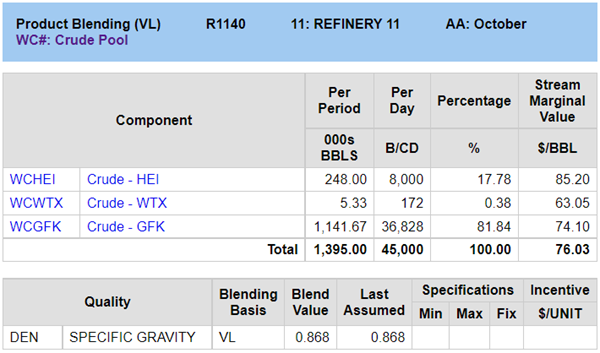
The pool density now reflects its composition. You could also bring in other whole crude properties such as sulphur and TAN so that you can report and control those.
So crudes can be pools too, and pools can be fed to distillation units – allowing you to optimize your crude slate more realistically if your logistics require exactly the same mixture to multiple towers. (If you want a similar slate, but not exactly the same – or are running a pure linear model – go back to the previous note for a description of a linear-approximation that will give you some control. I suspect that this sort of pooling will also be useful in modelling crude distribution networks, where crudes end up sharing tanks at some locations before arriving at their end uses – and so need to be treated as mixtures instead of independent streams.
26th November 2021.
You may also use this form to ask to be added to the distribution list so that you are notified via e-mail when new articles are posted.