The trend towards larger and larger models works against fast run times. If you are adding many crudes, periods and / or locations, adjusting the OMNI settings for your GRTMPS model might help speed things up again, particularly if you have seen a real step change in process time for matrix generation or reporting (something like more than doubling). It might even be essential to keep it running.
The GRTMPS.PGB program that does the matrix generation, recursion updates and base reporting is written in OMNI. OMNI is a specialist modelling language belonging to Haverly. It has been around for a long time, as computer software goes, and has settings that reflect its origins in days when computer memory was a scarce resource that had to be carefully managed. The settings are managed via the g5 user interface, on the Model node, for both database and table based models. They apply at the model level, and so are set once for all the cases. A new database will always have these default values:
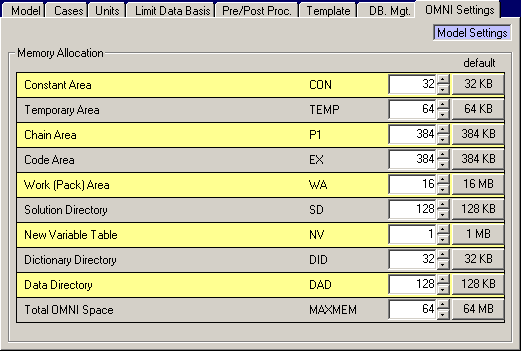
To prevent OMNI from grabbing all the memory, it has a MAXMEM setting, which defaults to 64 MB, as you can see at the bottom of the grid This memory is then allocated into partitions for specific uses, such as the data directory (DAD), to track the names and sizes of the data tables, with the balance going to the DDA space, which holds the data itself. Constant Area (CON), Temporary Area (TEMP), Chain Area (P1) and Code Area (EX) requirements are all a function of the matrix generation program, (the "PGB"). Leave them at the default values unless you are running some custom alternative program and find that it requires more.
The Work (Pack) Area (WA), Solution Directory (SD), New Variable Table (NV), Dictionary Directory (DID) and Data Directory (DAD) relate to the size of the model. They are automatically expanded during run time if not large enough. There will be messages in the LST file when this happens. For example: *W* 7A NV AREA EXPANDED BY 097184 with an accompanying NV AREA EXPANDED TO: 3539160 BYTES. To try to improve run speed, you can start by increasing allocation of any area which is being expanded, until there are no more warning messages. OMNI always talks about the memory in bytes - while the settings are in KB and MB so you need to divide by 1024 for KB, and then again for the MB that is used for the NV setting. That gives 3.375 MB in this case, to round up to 4 MB as only integer values are accepted. (Or you could just approximate and move the decimal over 6 places to say about 3.5, then round to 4). Always round up and add a bit of "wiggle room" as the worst performance is usually seen where the model fits, but just barely. The automatic resizing sometimes cannot be completed for the WA allocation, resulting in a *E* 26 PACK AREA OVERFLOW error. An increased Work Area allocation will resolve this problem, although it may take a few tries to find an adequate value. A *E* 43 DATA DIRECTORY OVERFLO error means that your DAD area needs to be increased. When you increase any settings, you might want to add a bit more to MAXMEM.
If you try to allocate so much memory to the partitions that there is clearly not going to be a reasonable amount of space for model data, then you will have a red dot warning, as here, where I have set the NV to 40 MB, while leaving the MAXMEM at 64 MB. The sum of CON, TEMP, P1, EX, WA, SD, NV, DID, DAD is allowed to be no more than 75% of MAXMEM.
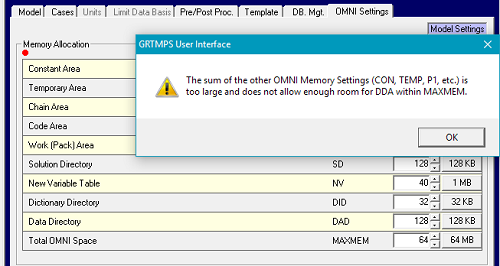
If your settings are possible, but the model is too large to fit, then you will have an error at run time, i.e. *E* 42 TABLE EXCEEDS DDA AREA or *E* 55 DICTDATA OVERFLOW ABORT. You should increase the MAXMEM, if there is room - or decrease the other partitions if MAXMEM is already at 2048 MB (the maximum memory that can be addressed by a 32-bit program) until the model runs through. You might also see improvements in run time from larger allocations, even if you already have no errors or warnings. In my experience the MAXMEM and NV settings have the most influence on performance, the NV particularly in reporting.
How big should MAXMEM be? The default of 64 MB is fine for our small demo models while only the very largest multi-location distribution or hundreds of crudes models will require the full 2GB. Larger can be better, but only up to a point. Once there is enough memory for the model to run well adding more will not reduce run times any further. Since OMNI will be competing with the other processes for resources, enough memory must be left for anything else you are doing at the same time - including other LP runs. The MAXMEM amount will be required for each simultaneous job when running with multi-core, for any of them on a step that is done by the PGB (matrix generation, recursion, report generation). So, if you have a laptop with 8 GB and you allocate the full 2048 MB, that is 2GB, for each run, then you would probably have trouble running more than 3 jobs at a time. Allocating 1GB, however, should allow you to run 6 or 7 jobs at a time (if you have enough CPUs). So you want to find the point at which the setting is large enough for best performance but no larger.
How to find your MAXMEM setting?
- Work with the largest sort of case you expect to run (the most crudes and the most periods).
- In order to get a time measurement you need to try to maintain a constant set of conditions during the runs - so one by one, and avoiding times when scans might be active etc.
- A "half-interval" (also known as binary) search algorithm is an efficient approach here. Run the minimum, median, and maximum values to divide the search range into two parts, a lower and upper interval. If the speed at the median is worse than the maximum, the next value to try is the half way point of the upper interval. If the original median was no better than the maximum, try the lower interval mid-point instead. Continue to take a value half way between the top and bottom of the better half until you find no change in run speed, for the degree of precision (size of range) that you are looking for (say 20 MB). So, for MAXMEM, start with 64, 1024 and 2048. If 2048 is faster than 1024, then try 1536. If 1536 is better than 1024, but no better than 2048, then try 1280, etc.
- It is not possible to use the Case Generator to vary the OMNI settings - they are written to TABLE R01.0 but any DATA,MODIFY would be overwritten by the user interface values at run time. So you are going to have to do this manually, changing the values in your database between runs, or make copies of the database with different settings.
- Look at the matrix generation and report times. The overall run time includes processes that are not affected by the OMNI settings, such as the optimization and simulation steps, and so may not show much impact. You can extract these timings from the SUM file, the "Run-Time Breakdown" at the end of the LST file, or the Queue Manager's Run Compare tool.
| Here is an example search for a good value. I used a typical refinery planning model with enough crudes active that it would not run with the default settings. The results show a typical step-change pattern. There are errors when the memory is too small (<= 154 MB) , a very slow run (20 minutes for matrix generation!) where the model just fits (169 MB), then stable performance once sufficient memory is available (>= 176). Based on these tests, I would set this model to 190 MB, leaving a bit of room for it to grow into. |
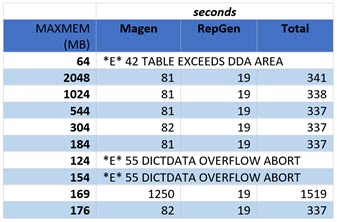 |
The next step is to adjust the NV. I did not expect a big effect as the report time was quick, and stable even when the memory was low. But there are expansions in the LST file, taking the allocation up to 5.1 MB. So I tried values from 6 MB to 15 MB, but without any effect as I anticipated. However, proving the point about the problem of just fitting, setting NV to 5 increased the generate time to 138s
So, in conclusion, the moral of the story is, the OMNI settings can influence performance. The absence of expansion messages or errors does not mean that you are in a good spot. It is worth doing some tests to be sure that you have not fallen into a bad spot, particularly if you have been making the model larger.
From Kathy's Desk 1st February 2017.
Comments and suggestions gratefully received via the usual e-mail addresses or here.
You may also use this form to ask to be added to the distribution list to be notified via e-mail when new articles are posted.