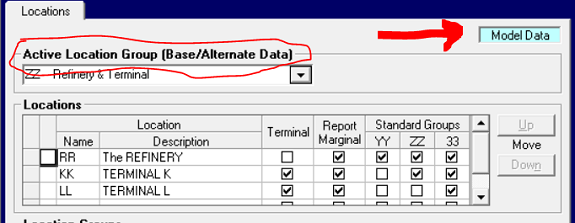
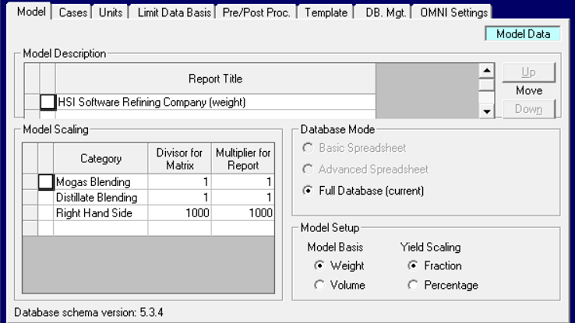
| The lists of objects which are used to construct the refinery (or petro-chemical plant, or pipeline system etc.) representation, are defined on Model Data panels. These include Locations, as shown above, Streams as shown here, Qualities, Loading Factors, Utilities and Cost Accounts. You only ever need to add an item to these lists once to have it available in every case (which is very convenient). If you change the code or description for any of these items it will automatically be updated everywhere that it is used in the database (very, very convenient). However, if it is not used for something, it will be ignored. So, for example, you could add a set of codes for new crudes to the Stream list, but if you don’t purchase them, there won’t be any new equations in the matrix. | 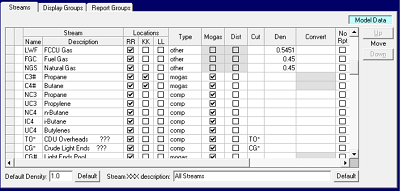 |
| Process unit representations in a full database model are also Model Data, as you can see here on Operations. Every other tab on a unit node, except Limits, is also Model Data. This means that if you edit anything here within the unit – the yields, the bounds on modes, the loadings on the limits, etc. – you will change that process unit for every case that uses it. That’s great if you want to update the model as a whole, but not at all useful if you want to make specific adjustments for an alternate case. (Oddly, the SSI file is Base/Alternate so you could use a different one in an alternate case, but if you Imported the data, it would change all the cases.) | 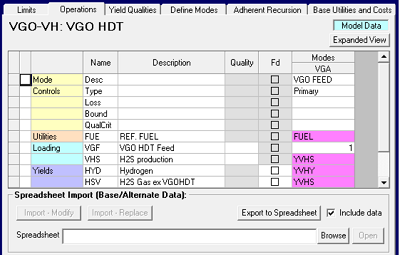 |
| More usefully, the Process Simulator file connected to a unit using adherent recursion as also Base/Alternate. You can have use files with different equations or reference data long as the Input/Output corresponds to the PUP definitions and generic structure in the process unit representation. | 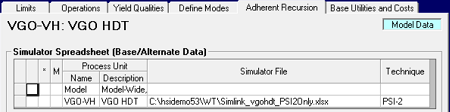 |
 |
 |
|
Base Case
|
Exer 2
|
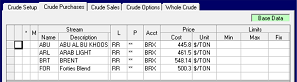
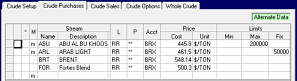
Compare the base case data in the panel on the right to the alternate case data in the panel on the left. The alternate case uses and displays the same data records as the base case, except where a value in the row has been changed. Those rows are marked with an “m”. Some limits have been added to the existing rows. You can sort on the “M” column in any grid; "Ascending" will cluster the modified records at the top. If you right-click on any one of these rows, you can choose to “Revert Back to Base Case Data". If you right-click on an “m” row and the revert is not offered, then the record has been added in the alternate case and does not have corresponding base data.
Now observe what happens if I change the prices in the base case.
|
Base Case
|
Exer 2
|
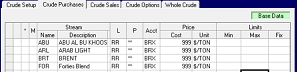
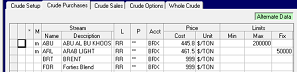
Sometimes when you change a row, the original will appear commented out, while the revision is added as a new row. Crude Set up modifications work that way. If you change the file locations in an alternate case, you will end up with a double list of commented and active records. Sorting Ascending on "M" will make this easier to work with.
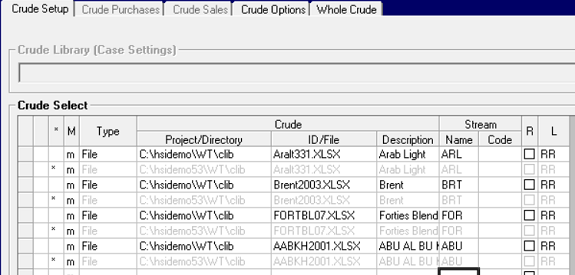
Group member lists for combined limits in purchases, sales, inventory and transportation etc. are Base/Alternate , but better set up in the base case so that they are consistently defined within the model. The Group itself behaves like Model Data and will be visible in all cases. If you are not careful, you might get an unpleasant surprise, like a limit with no contributions. In cases without limits the group will be ignored. So, go for the no "m" option. And if you have set up a membership list in an alternate case you can move it with just a copy and paste into the grid in the base case. When you go back to the alternate case afterwards the "m"'s will be gone.
|
|
 |
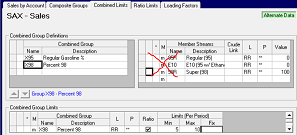
Specifications and blend logic are also done with Base/Alternate , so a new product could be set up entirely in an alternate case. Again it is smarter to put this information in the base case. If you put it in an alternate case, there is a risk that the product stream will be selected for sale in some other case, not copied from the right alternate, without any indication that there happens to be no spec and / or no components . So put it in the base case and use the Product Screening option on the Generate Matrix panel (a Case Setting) and it will be turned off in the cases where it is not sold.
| The Alternate functionality, however, is just what you need when the point of the case is a change in group membership, specifications or blend logic. Exer8a in the Wt Demo model is about looking at using Naphtha as a diluent in heavier fuel oils. The Blend logic modifications for that are shown in yellow like this. This is the only panel where modification is tracked by individual cell, rather than the whole row. | 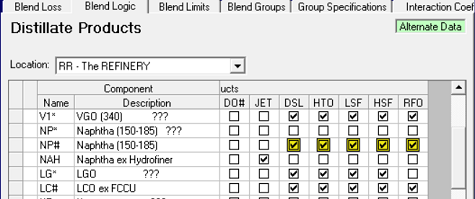 |
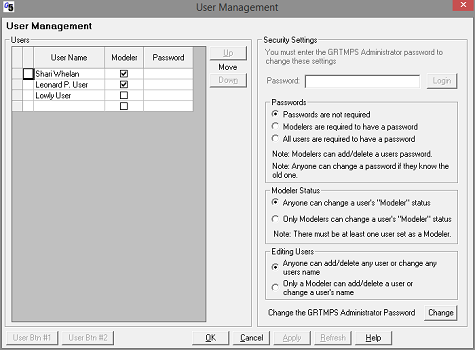
And finally, the data types are also about who is allowed to change what. Some of the clients who helped us with the initial design for the database input system were worried about un-authorized changes to the model. So we developed the database equivalent of making your master.xlsx file read only. Shari Whelan explains. Click on the User | Management menu item. This opens the "User Management" panel, where you can setup different users. Mine is seen in the screen capture. Leonard and I are Modelers, but poor Lowly is just a user.
 |
|
- Case Settings: Only modelers can edit the base case's data.
- Model Data: Only modelers can edit this data
- Model Settings: Both modelers and users can edit this data
- Base/Alternate: Only modelers can make changes in the base case.
- Case Specific: This is a special one that we setup for the "Process Unit List" and "Recipe List" panels. The purpose of this design is to allow non-modelers (aka "users) to make a copy of a unit (or recipe) and then be able to fully edit the copy. Only modelers can make changes in the Base case. The "Base" column is only editable in the Base case. A check in the Base column means the unit is "owned" by the Base case. Only modelers can edit units that are owned by the Base case. Units that are not owned by the base case can be edited by users. What this means is that every panel under a "Process Units | [unit]", where [unit] is not owned by the Base case, can be edited by a non-modeler ... even panels marked as "Model Data". Got it?
As far as I know, however, everyone has decided it's easier just to trust people to not edit what they shouldn't, so we're all modellers. (And if you can't resist, remember to clear out the change log to get rid of the evidence.)
From Kathy's Desk 24th August 2017.
Comments and suggestions gratefully received via the usual e-mail addresses or here.
You may also use this form to ask to be added to the distribution list so that you are notified via e-mail when new articles are posted.